|
|
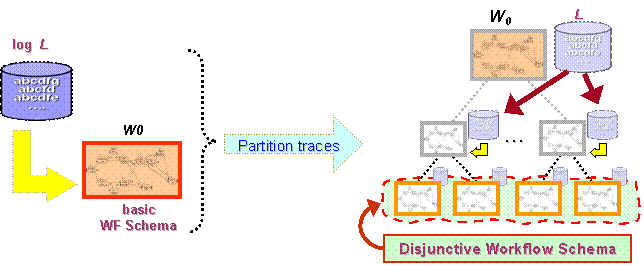
Overview of the approachThe discovery of a disjunctive schema WS for a given log, is carried out in an efficient way, through an iterative, hierarchical refinement of the process model. The basic idea is sketeched in the following figure.
The approach starts by mining a preliminary workflow schema W0, which is a first attempt to model the whole log. This schema, along with the log traces, corresponds to the root of a tree shown in the right side of the figure. Iteratively, one of the schemata that have not been refined yet (i.e., that correponds to some leaf of the tree) is refined: the set of traces that are associated with it are split into clusters, and a new schema is eventually mined for each of these clusters. By the way, any classical process mining technique could be exploited to mine any of the above workflow schemata, once homogeneous clusters of traces have been recognized. At the end of the process, a disjunctive process model is obtained that consists of all the schemata at the leaves, and represents the log in a more accurate than W0. How to cluster log tracesIn order to efficiently partition a set of traces into clusters by means of well-known methods, we resort to a “flat” relational representation of the traces, by projecting them onto a set of features. Such features, called discriminant rules, are meant to characterize behavioral patterns which are not properly modelled by the current workflow schema being refined. In particular, a discriminant rule is a rule of the from [a1 …ah ] -/-> a such that:
n
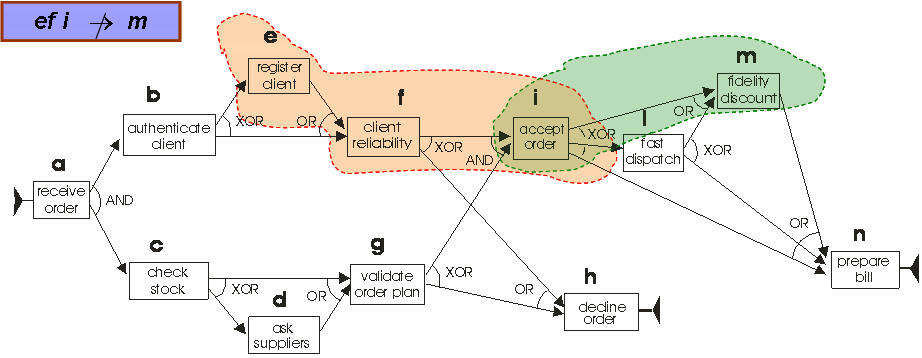
The following figure shows an example of
such rule for a workflow model handling the management of an order. The
rule simply capture the fact that a fidelity discount (task m) is
never applied when the registration of the (new) client has been performed
(task e).
n
Furhter details on the approach can be found in Mining Expressive Process Models by Clustering Workflow Traces, and in other works listed in section References. |
|
|